Netty中的内存管理
通过之前的博客,大家可能已经知道整个gRPC是如何通信的了,因此对Netty也有了一定的了解,但是博主一直很困惑,Netty是如何控制内存的呢,完全异步化的世界里,各个Frame都是独立的,其中的数据在某一时刻或者某一中间状态时也是安静的躺在内存里,等待处理,稍有不慎就会发生内存泄漏,Netty又是如何防止这些情况的呢,让我们从DirectByteBuffer开始说起。
DirectByteBuffer堆外内存
DirectByteBuffer是Java用于实现堆外内存的一个重要类,我们可以通过该类实现堆外内存的创建、使用和销毁。
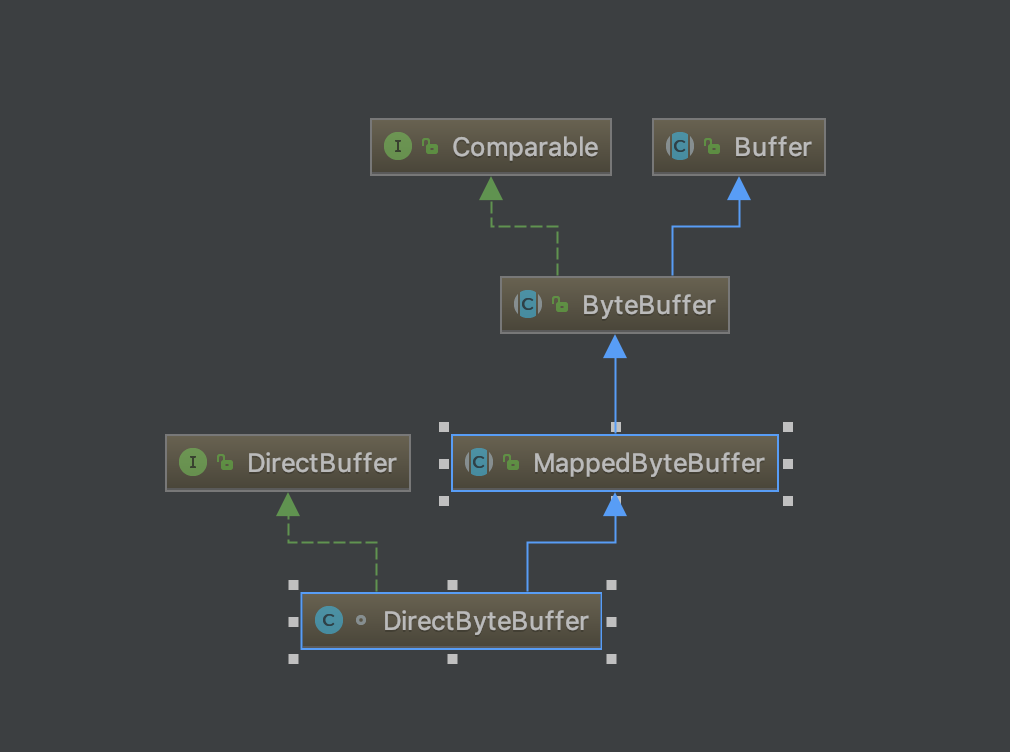
DirectByteBuffer该类本身还是位于Java内存模型的堆中。堆内内存是JVM可以直接管控、操纵。
而DirectByteBuffer中的unsafe.allocateMemory(size);是个一个native方法,这个方法分配的是堆外内存,通过C的malloc来进行分配的。分配的内存是系统本地的内存,并不在Java的内存中,也不属于JVM管控范围,所以在DirectByteBuffer一定会存在某种方式来操纵堆外内存。
在DirectByteBuffer的父类Buffer中有个address属性:
// Used only by direct buffers
// NOTE: hoisted here for speed in JNI GetDirectBufferAddress
long address;
address表示分配的堆外内存的地址,JNI后续的调用也是用的这个值,那么DirectByteBuffer是如何分配的呢?
// Primary constructor
//
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap);
long base = 0;
try {
//分配内存
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
//这里注意,Cleaner是一个PhantomReference,跟踪DirectByteBuffer对象的垃圾回收,以实现当DirectByteBuffer被垃圾回收时,堆外内存也会被释放
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}
unsafe.allocateMemory(size);分配完堆外内存后就会返回分配的堆外内存基地址,并将这个地址赋值给了address属性。这样我们后面通过JNI对这个堆外内存操作时都是通过这个address来实现的了。PS: Cleaner是一个PhantomReference,不了解的同学参照:JAVA引用
看来DirectByteBuffer的回收是利用了PhantomReference,具体的回收细节在Deallocator,无非是通过C重新释放内存,并且在Cleaner的代码里也能清楚地看到,如果释放内存失败,那么这个JVM会直接退出,避免内存泄漏带来的隐患。
public void clean() {
if (remove(this)) {
try {
this.thunk.run();
} catch (final Throwable var2) {
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
if (System.err != null) {
(new Error("Cleaner terminated abnormally", var2)).printStackTrace();
}
System.exit(1);
return null;
}
});
}
}
}
Bits.reserveMemory(size, cap);方法,有兴趣的同学可以看看,这个方法主要是保证系统中有可用的内存进行分配,总的来说,Bits.reserveMemory(size, cap)方法在可用堆外内存不足以分配给当前要创建的堆外内存大小时,会实现以下的步骤来尝试完成本次堆外内存的创建:
- 触发一次非堵塞的
Reference.tryHandlePending(false)。该方法会将已经被JVM垃圾回收的DirectBuffer对象的堆外内存释放。 - 如果进行一次堆外内存资源回收后,还不够进行本次堆外内存分配的话,则进行
System.gc()。System.gc()会触发一个full gc,但你需要知道,调用System.gc()并不能够保证Full GC马上就能被执行。所以在后面打代码中,会进行最多9次尝试,看是否有足够的可用堆外内存来分配堆外内存。并且每次尝试之前,都对延迟等待时间,已给JVM足够的时间去完成Full GC操作。 注意,如果你设置了-XX:+DisableExplicitGC,将会禁用显示GC,这会使System.gc()调用无效。 - 如果9次尝试后依旧没有足够的可用堆外内存来分配本次堆外内存,则抛出
OutOfMemoryError(“Direct buffer memory”)异常。
Netty内存池
内存分类
看来堆外内存的回收是借用了PhantomReference引用机制,他的回收时机依赖DirectByteBuffer,真相大白,原来堆外内存回收是这么回事。
那么问题来了,高并发场景下,如果堆外内存回收过慢,那不是很容易出现OOM么?
是的,很容易出现,我们做Young GC的时候会将新生代里的不可达的DirectByteBuffer对象及其堆外内存回收了,但是无法对old里的DirectByteBuffer对象及其堆外内存进行回收,这也是我们通常碰到的最大的问题。( 并且堆外内存多用于生命期中等或较长的对象 )。
且慢,我们来看看gRPC中通信使用的是啥。
NettyWritableBuffer,乍一看去,好像也没什么了不起,只不过封装了一层ByteBuf,我们深入看下内存的分配器:NettyWritableBufferAllocator,终于,让我们翻到了gRPC使用的内存分配器:
PooledByteBufAllocator和UnpooledByteBufAllocator,当然还有PreferHeapByteBufAllocator。
PreferHeapByteBufAllocator显而易见,是使用堆内存的分配器,那Pool和不Pool又是啥?其实这里就出现了Netty中的内存池的概念。
PooledByteBuf<T>:基于内存池的ByteBuf,主要为了重用ByteBuf对象,提升内存的使用效率;适用于高负载,高并发的应用中。主要有PooledDirectByteBuf,PooledHeapByteBuf,PooledUnsafeDirectByteBuf三个子类,PooledDirectByteBuf是在堆外进行内存分配的内存池ByteBuf,PooledHeapByteBuf是基于堆内存分配内存池ByteBuf,PooledUnsafeDirectByteBuf也是在堆外进行内存分配的内存池ByteBuf,区别在于PooledUnsafeDirectByteBuf内部使用基于PlatformDependent相关操作实现ByteBuf,具有平台相关性。
原来如此,原来为了提升堆外内存的利用率,又把内存分成了:
- 基于内存池的
ByteBuf:优点是可以重用ByteBuf对象,通过自己维护一个内存池,可以循环利用创建的ByteBuf,提升内存的使用效率,降低由于高负载导致的频繁GC。适用于高负载,高并发的应用中。推荐使用基于内存池的ByteBuf。 - 非内存池的
ByteBuf:优点是管理和维护相对简单。
当然,通过源码ByteBufUtil里能看出来,Netty默认还是使用的PooledByteBufAllocator:
static {
MAX_BYTES_PER_CHAR_UTF8 = (int)CharsetUtil.encoder(CharsetUtil.UTF_8).maxBytesPerChar();
String allocType = SystemPropertyUtil.get("io.netty.allocator.type", PlatformDependent.isAndroid() ? "unpooled" : "pooled");
allocType = allocType.toLowerCase(Locale.US).trim();
Object alloc;
if ("unpooled".equals(allocType)) {
alloc = UnpooledByteBufAllocator.DEFAULT;
logger.debug("-Dio.netty.allocator.type: {}", allocType);
} else if ("pooled".equals(allocType)) {
alloc = PooledByteBufAllocator.DEFAULT;
logger.debug("-Dio.netty.allocator.type: {}", allocType);
} else {
//默认使用 PooledByteBufAllocator
alloc = PooledByteBufAllocator.DEFAULT;
logger.debug("-Dio.netty.allocator.type: pooled (unknown: {})", allocType);
}
DEFAULT_ALLOCATOR = (ByteBufAllocator)alloc;
...
}
那么内存池究竟是什么呢?
内存管理PoolArena、PoolSubpage、PoolChunk
PoolArena
首先明确两个概念:
PageSize:可以分配的最小的内存块单位,默认8192。Chunk: 一堆Page的集合,Chunk的大小=pageSize«maxOrder(默认11)。
由于Netty通常应用于高并发系统,不可避免的有多线程进行同时内存分配,可能会极大的影响内存分配的效率,为了缓解线程竞争,可以通过创建多个PoolArena细化锁的粒度,提高并发执行的效率,首先我们看看PoolArena的内部结构:
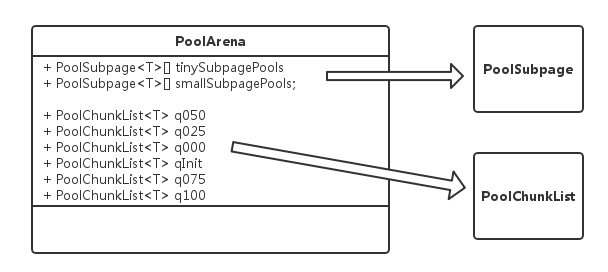
PoolChunk:维护一段连续内存,并负责内存块分配与回收。PoolSubpage:将Page分为更小的块进行维护;PoolChunkList:维护多个PoolChunk的生命周期。- 多个
PoolChunkList也会形成一个List,方便内存的管理。最终由PoolArena对这一系列类进行管理,PoolArena本身是一个抽象类,其子类为HeapArena和DirectArena,对应堆内存(Heap Buffer)和堆外内存(Direct Buffer),除了操作的内存(byte[]和ByteBuffer)不同外两个类完全一致。
PoolChunk
我们先来看一幅图:
上图一个默认大小的Chunk, 由2048个Page组成了一个Chunk,一个Page的大小为8192, Chunk之上有12层节点,最后一层节点数与Page数量相等。每次内存分配需要保证内存的连续性,这样才能简单的操作分配到的内存,因此这里构造了一颗完整的平衡二叉树,所有子节点的管理的内存也属于其父节点。如果我们想获取一个8K的内存,则只需在第11层找一个可用节点即可,而如果我们需要16K的数据,则需要在第10层找一个可用节点。如果一个节点存在一个已经被分配的子节点,则该节点不能被分配,例如我们需要16K内存,这个时候id为2048的节点已经被分配,id为2049的节点未分配,就不能直接分配1024这个节点,因为这个节点下的内存只有8K了。
PoolSubpage
前面我们讲过了负责内存分配的类PoolChunk,它最小的分配单位为Page, 而默认的page size为8K。在实际的应用中,会存在很多小块内存的分配,如果小块内存也占用一个Page明显很浪费,针对这种情况,可以将8K的Page拆成更小的块,这已经超出Chunk的管理范围了,这个时候就出现了PoolSubpage, 其实PoolSubpage做的事情和PoolChunk做的事情类似,只是PoolSubpage管理的是更小的一段内存。
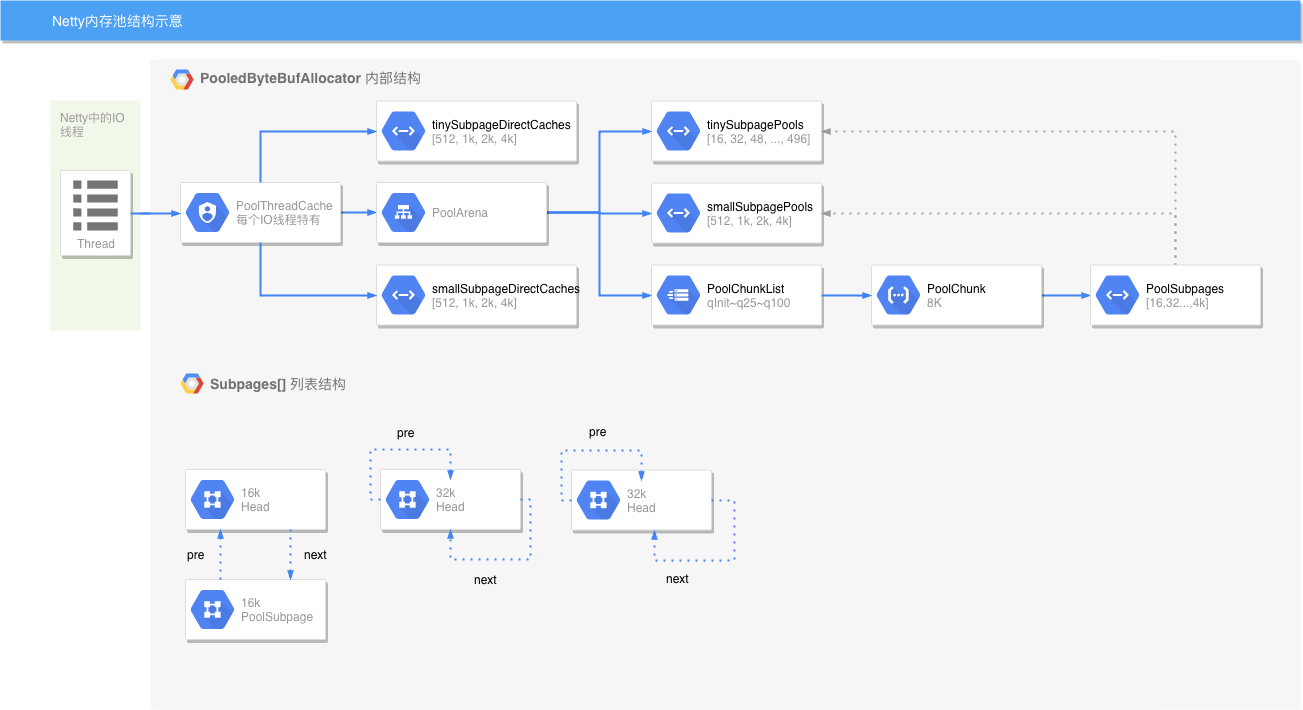
组件结构图
 其中
其中link list就是各个PoolChunkList的链表,在PoolArena中进行维护,也就是俗称的那些q00,q100那些链表,这里不详细展开,有个概念就行。
内存池内存分配流程:
看完上述,最后总结一下Netty的内存分配流程:
ByteBufAllocator准备申请一块内存;- 尝试从PoolThreadCache中获取可用内存,如果成功则完成此次分配,否则继续往下走,注意后面的内存分配都会加锁;
- 如果是小块(可配置该值)内存分配,则尝试从PoolArena中缓存的PoolSubpage中获取内存,如果成功则完成此次分配;
- 如果是普通大小的内存分配,则从PoolChunkList中查找可用PoolChunk并进行内存分配,如果没有可用的PoolChunk则创建一个并加入到PoolChunkList中,完成此次内存分配;
- 如果是大块(大于一个Chunk的大小)内存分配,则直接分配内存而不用内存池的方式;
- 内存使用完成后进行释放,释放的时候首先判断是否和分配的时候是同一个线程,如果是则尝试将其放入PoolThreadCache,这块内存将会在下一次同一个线程申请内存时使用,即前面的步骤2;
- 如果不是同一个线程,则回收至Chunk中,此时Chunk中的内存使用率会发生变化,可能导致该Chunk在不同的PoolChunkList中移动,或者整个Chunk回收(Chunk在q000上,且其分配的所有内存被释放);同时如果释放的是小块内存(与步骤3中描述的内存相同),会尝试将小块内存前置到PoolArena中,这里操作成功了,步骤3的操作中才可能成功。
在PoolThreadCache中分了tinySubPageHeapCaches、smallSubPageHeapCaches、normalSubPageHeapCaches三个数组,对应于tiny\small\normal在内存分配上的不同(tiny和small使用subpage,normal使用page),整个Netty内存池的数据结构如下图所示:
 后续博客有时间会深入研究一下各个组件的源码,尽情期待。
后续博客有时间会深入研究一下各个组件的源码,尽情期待。